James-Stein Estimation and Shrinkage
STA 721: Lecture 10
Negative Shrinkage?
one potential problem with the James-Stein estimator \[\tilde{\boldsymbol{\beta}}_{JS} = \left(1 - \frac{(p-2)\sigma^2}{\|\hat{\boldsymbol{\beta}}\|^2} \right) \hat{\boldsymbol{\beta}}\] is that the term in the parentheses can be negative if \(\|\hat{\boldsymbol{\beta}}\|^2 < (p-2)\sigma^2\)
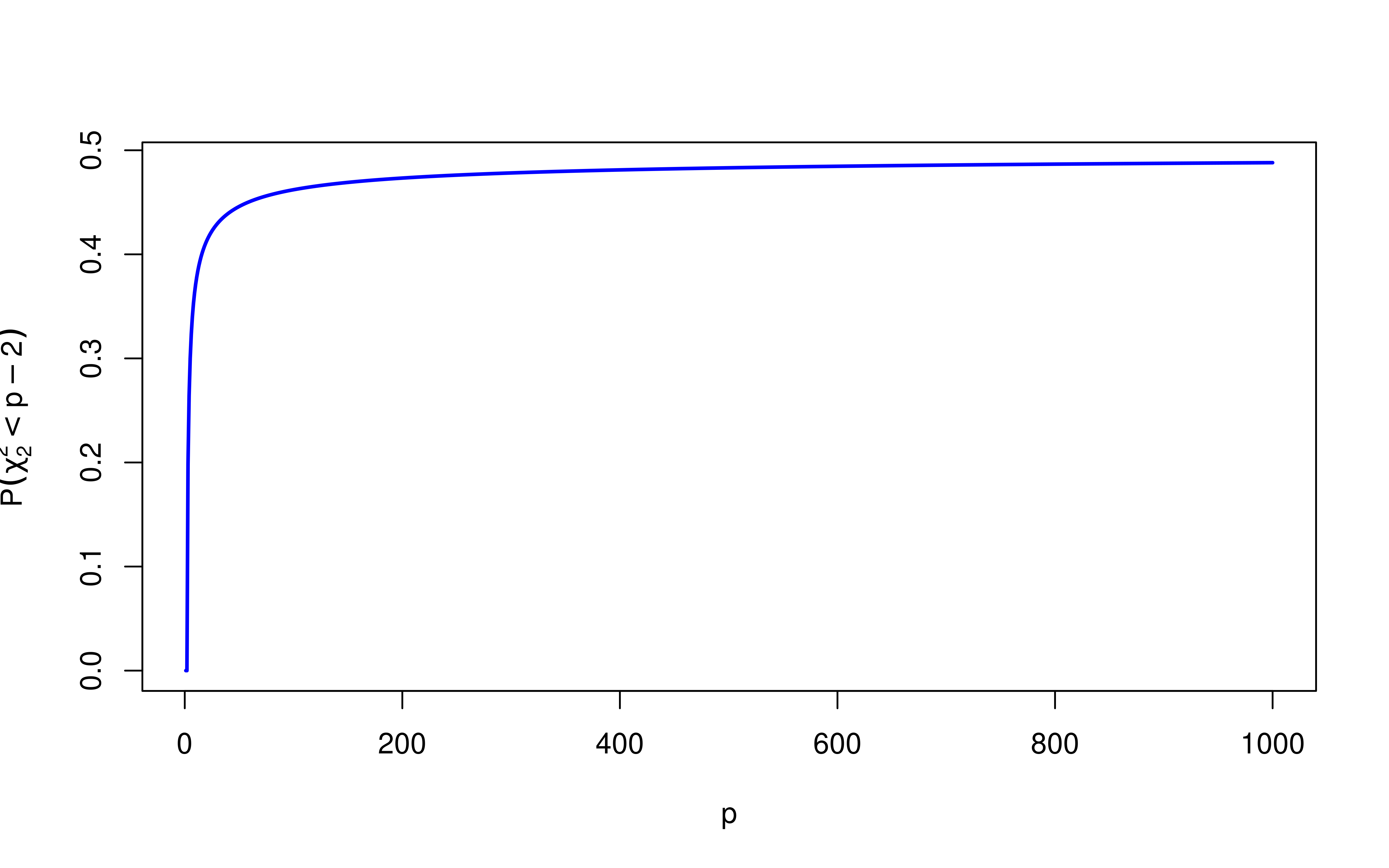
How likely is this to happen?
Suppose that each of the parameters \(\beta_j\) are actually zero, then \(\hat{\boldsymbol{\beta}}\sim \textsf{N}(\mathbf{0}_p, \sigma^2 \mathbf{I}_p)\) then \(\|\hat{\boldsymbol{\beta}}\|^2 /\sigma^2 \sim \chi^2_p\)
compute the probability that \(\chi^2_p < (p-2)\)
so if the model is full of small effects, the James-Stein can lead to negative shrinkage!
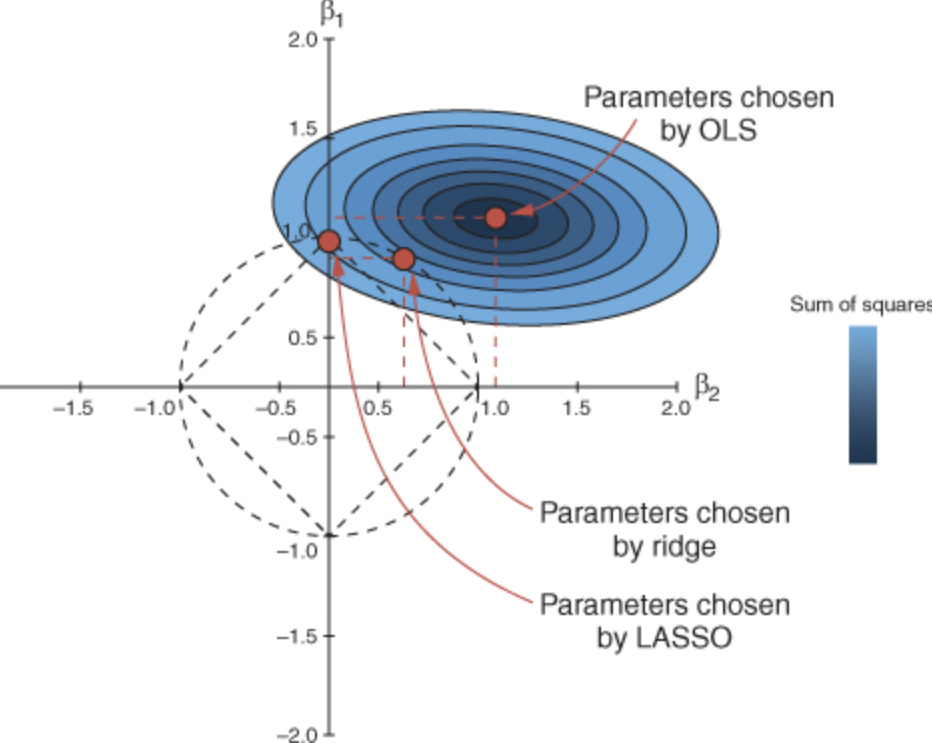
LASSO Estimator
an alternative estimator that allows for shrinkage and selection is the LASSO (Least Absolute Shrinkage and Selection Operator).
the LASSO replaces the penalty term in the ridge regression with an \(L_1\) penalty term \[\hat{\boldsymbol{\beta}}_{LASSO} = \mathop{\mathrm{argmin}}_{\boldsymbol{\beta}} \left\{ \|\mathbf{Y}- \mathbf{X}\boldsymbol{\beta}\|^2 + \lambda \|\boldsymbol{\beta}\|_1 \right\}\]
the LASSO can also be shown to be the posterior mode of a Bayesian model with independent Laplace or double exponential prior distributions on the coefficients.
as the double exponential prior is a “scale” mixture of normals, this provides a generalization of the ridge regression.