Shrinkage Estimators and Hierarchical Bayes
STA 721: Lecture 11
LASSO Estimator
Tibshirani (JRSS B 1996) proposed estimating coefficients through \(L_1\) constrained least squares via the Least Absolute Shrinkage and Selection Operator or lasso \[\hat{\boldsymbol{\beta}}_{L} = \mathop{\mathrm{argmin}}_{\boldsymbol{\beta}} \left\{ \|\mathbf{Y}_c - \mathbf{X}_s \boldsymbol{\beta}\|^2 + \lambda \|\boldsymbol{\beta}\|_1 \right\}\]
\(\mathbf{Y}_c\) is the centered \(\mathbf{Y}\), \(\mathbf{Y}_c = \mathbf{Y}- \bar{\mathbf{Y}} \mathbf{1}\)
\(\mathbf{X}_s\) is the centered and standardized \(\mathbf{X}\) matrix so that the diagonal elements of \(\mathbf{X}_s^T\mathbf{X}_s = c\).
use the
scalefunction but standardization usually handled within packages
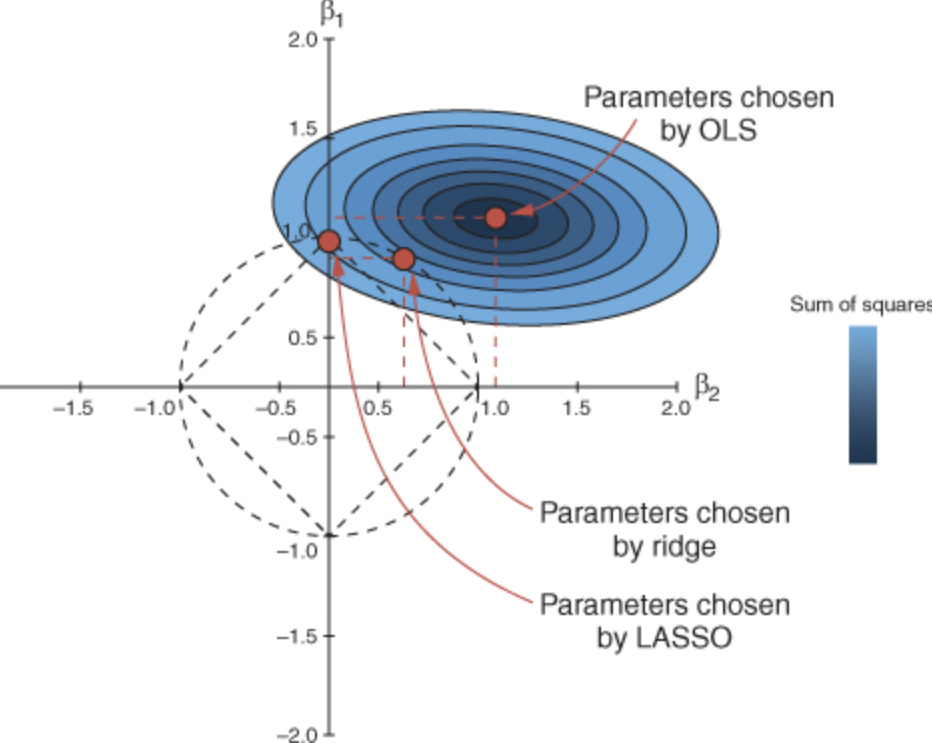
Control how large coefficients may grow \[\arg \min_{\boldsymbol{\beta}} (\mathbf{Y}_c - \mathbf{X}_s \boldsymbol{\beta})^T (\mathbf{Y}_c - \mathbf{X}_s\boldsymbol{\beta})\]
\[ \text{ subject to } \sum |\beta_j| \le t\]
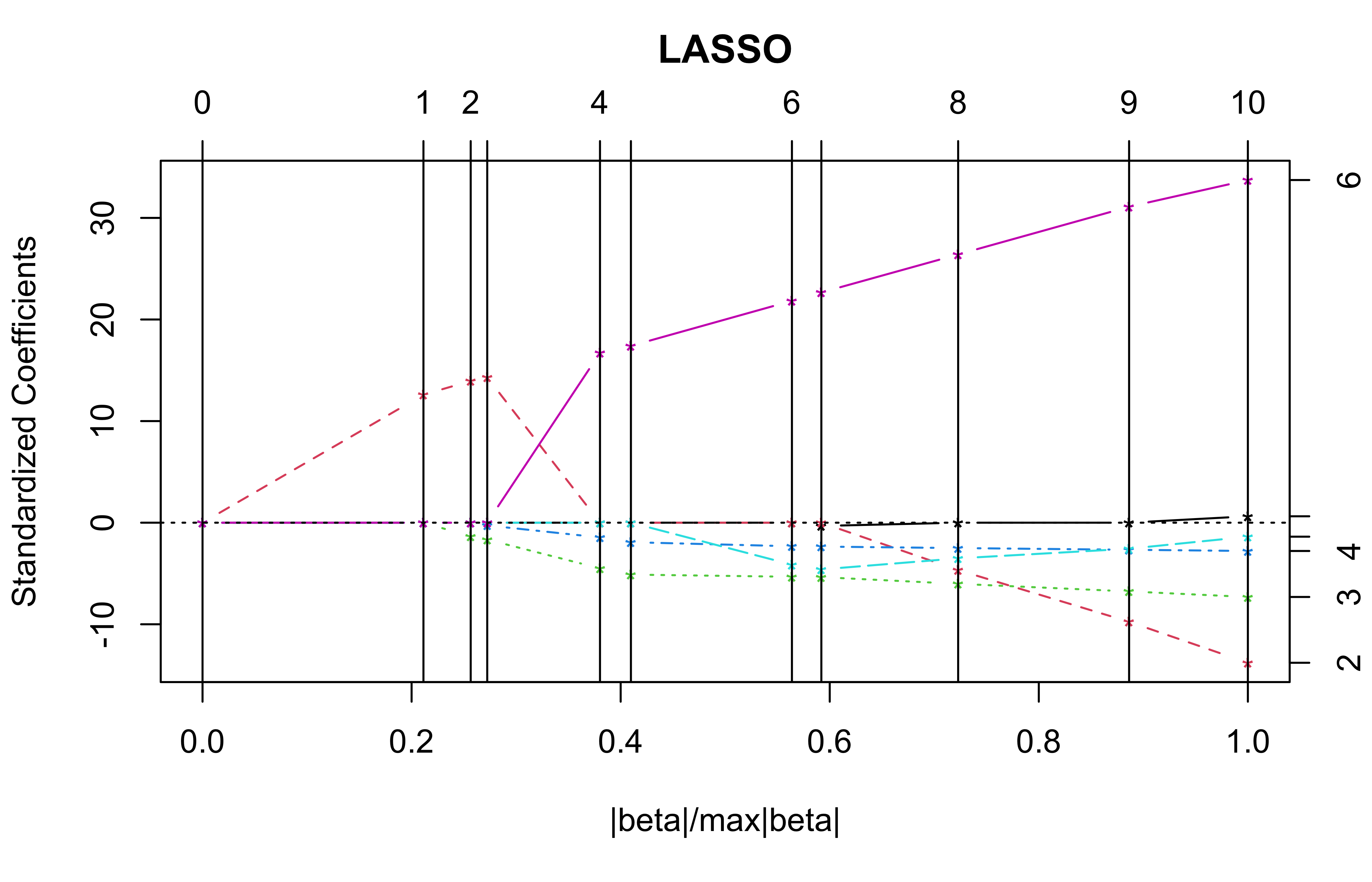
Lasso Solutions
The entire path of solutions can be easily found using the ``Least Angle Regression’’ Algorithm of Efron et al (Annals of Statistics 2004)
Special Case
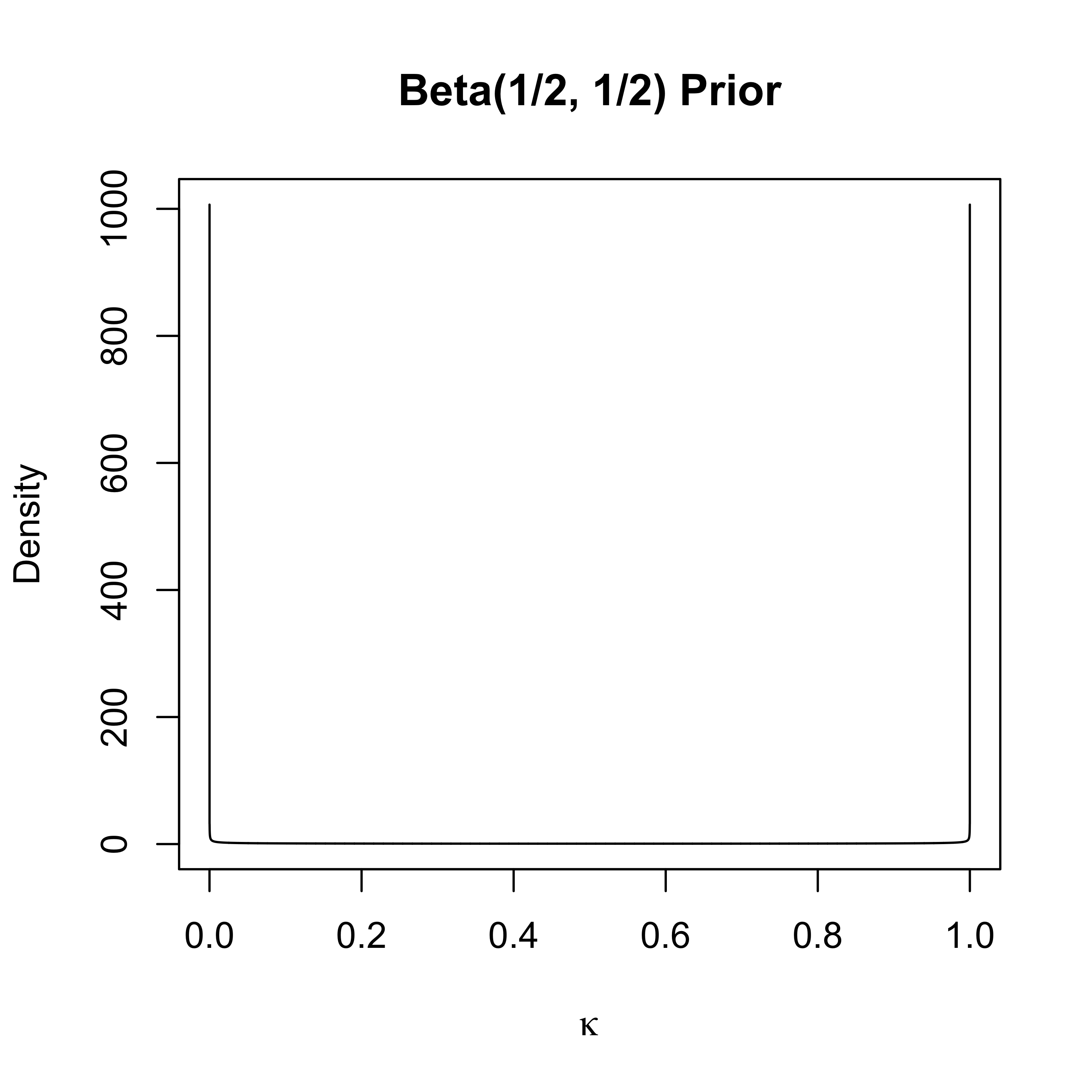
In the case \(\lambda = \phi = 1\) and with \(\mathbf{X}^t\mathbf{X}= \mathbf{I}\), \(\mathbf{Y}^* = \mathbf{X}^T\mathbf{Y}\) \[\begin{align*} E[\beta_i \mid \mathbf{Y}] & = \textsf{E}_{\kappa_i \mid \mathbf{Y}}[ \textsf{E}_{\beta_i \mid \kappa_i, \mathbf{Y}}[\beta_i \mid \mathbf{Y}] \\ & = \int_0^1 (1 - \kappa_i) y^*_i p(\kappa_i \mid \mathbf{Y}) \ d\kappa_i \\ & = (1 - \textsf{E}[\kappa \mid y^*_i]) y^*_i \end{align*}\] where \(\kappa_i = 1/(1 + \tau_i^2)\) is the shrinkage factor (like in James-Stein)
- Half-Cauchy prior induces a Beta(1/2, 1/2) distribution on \(\kappa_i\) a priori (change of variables)
Features and Issues
the posterior mode also induces shrinkage and variable selection if the mode is at zero
the posterior mean is a shrinkage estimator (no selection)
the tails of the distribution are heavier than the Laplace prior (like a Cauchy distribution) so that there is less shrinkage of large \(|\hat{\boldsymbol{\beta}}|\).
Desirable in the orthogonal case, where lasso is more like ridge regression (related to bounded influence)
MCMC is slow to mix using programs like
stanbut specializedRpackages likehorseshoeandmonomvn::bhsare available
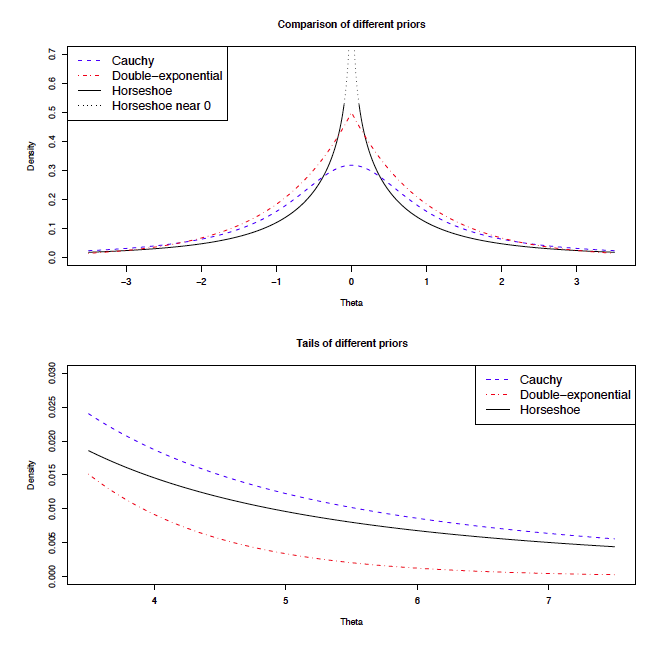
Bounded Influence and Posterior Mean
Posterior mean of \(\beta\) may also be written as \[E[\beta_i \mid y^*_i] = y^*_i + \frac{d} {d y} \log m(y^*_i)\] where \(m(y)\) is the predictive density \(y^*_i\) under the prior (known \(\lambda\))
HS has Bounded Influence: \[\lim_{|y| \to \infty} \frac{d}{dy} \log m(y) = 0\]
\(\lim_{|y_i^*| \to \infty} E[\beta_i \mid y^*_i) \to y^*_i\) (the MLE)
since the MLE \(\to \beta_i^*\) as \(n \to \infty\), the HS is asymptotically consistent
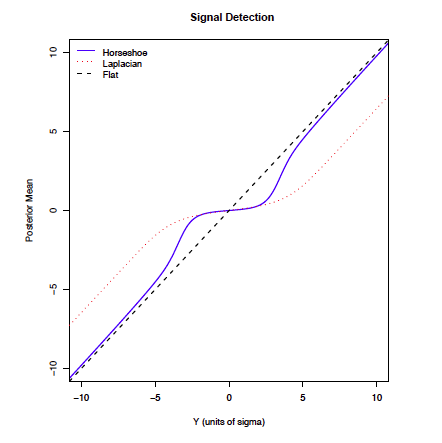
- the DE also has bounded influence, but the bound does not decay to zero in tails so that the posterior mean does not shrink to the MLE
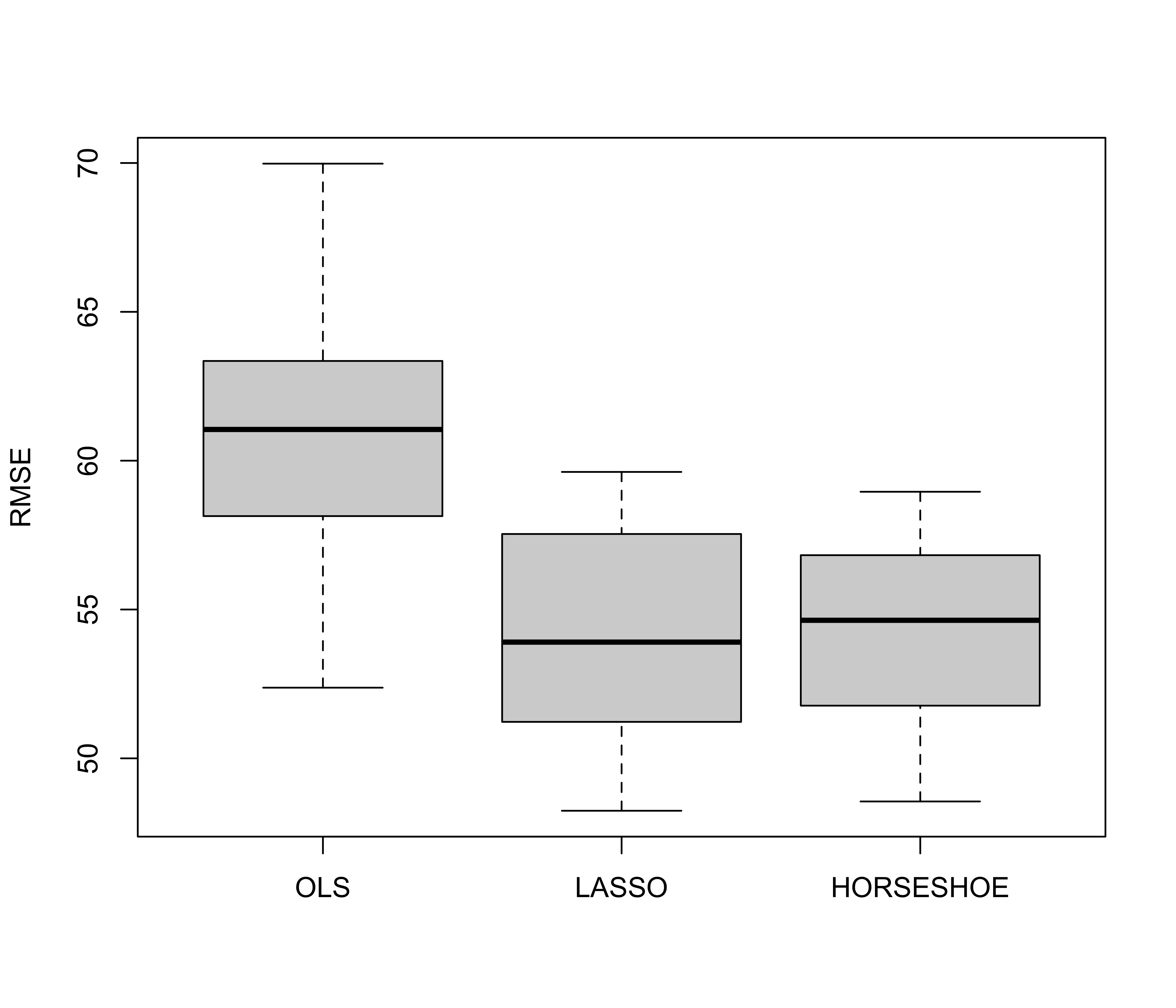
Comparison
Diabetes data (from the
larspackage)64 predictors: 10 main effects, 2-way interactions and quadratic terms
sample size of 442
split into training and test sets
compare MSE for out-of-sample prediction using OLS, lasso and horseshoe priors
Root MSE for prediction for left out data based on 25 different random splits with 100 test cases